
Part 5: Optimizing Performance
In Part 4, we observed that force inputs on the MatrixArray were detected in the correct location. Readings were proportional to force, and came reasonably close to spanning full scale ADC range. Analog performance looks satisfactory, so let's focus on speed.
We previously observed that a full scan cycle took about 57msec to complete (17Hz update rate), which is too slow for most projects, especially when measuring user touch inputs.
You may have already spotted some (glaring) innefficiency in the initial Arduino code example. Referring again to the scope view at right, let's look some key areas where we can probably make some major speed improvements.
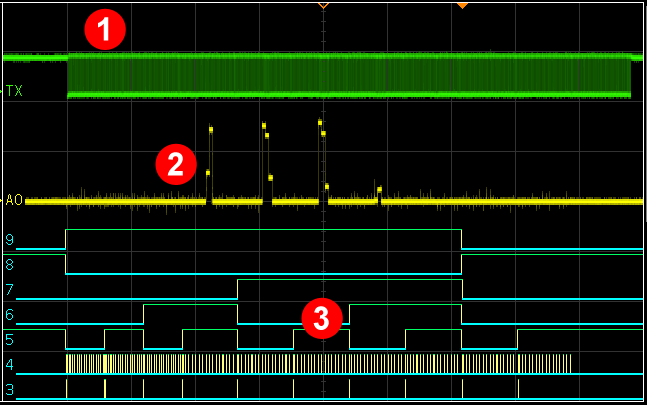
1. Serial Communication
Looking at the TX pin, we can see the primary bottleneck of this system. Even if the hardware scanned faster, we'd still have to wait for serial transfers to complete before we could proceed with the next scan.
In the initial Arduino code example, we sent 3 bytes per reading, plus line endings, to keep consistent / readable text spacing in the terminal window.
If we reduce each reading to single byte and remove line breaks, we can instantly making Serial communication over 3x faster. Of course this will make a mess of the terminal window, so we'll create our own receiving app in Part 8.
We also notice long strings of zeros, so we'll apply simple compression, sending consecutive zero values as a single zero + count. For example, given a string of 100 zeros in a row, we will send "0", then "100" - 2 bytes instead of 100.
2. ADC Conversion Rate
Each ADC conversion takes about 100usec using default ADC configuration. We're taking 160 readings per scan cycle, so that's 16msec total. We'll reduce that by reducing the ADC prescaler to the minimum value that still provides good readings.
3. IO Speed / digitalWrite()
Using external IO (shift registers and muxes) means flipping a lot of bits to scan the MatrixArray - we're making nearly 400 calls to digitalWrite() per scan cycle.
We'll replace digitalWrite with direct port manipulation. Direct port manipulation has already been discussed extensively on other sites, so we'll skip the full explanation here, but we should be able to shave a millisecond or two off of each scan cycle.